Exploring Jane Austen novels with text analysis

- Data setup
- Vocabulary Comparison
- Word Frequencies
- “Do they do anything except talk?”
- Story Highs and Lows
- Character Appearances
- Character Networks
- Conclusion
- Code
This post will detail the exploration of three novels by Jane Austen: Emma, Pride and Prejudice, Sense and Sensibility.
I used Python, relying primarily on the pandas, re, and nltk libraries. The visualizations were generated using the Bokeh library.
The code can be applied to any combination of books, with a few modifications.
Data setup
Raw text files for the novels were acquired courtesy of Project Gutenberg, a website that hosts books not protected by U.S. copyright law, usually due to copyright expiration.
I downloaded the Plain Text UTF-8 options for each book:
Project Gutenberg adds extra license and disclaimer information before and after the actual text of each novel, so it was necessary to split the text files on the delimiters, such as the title/author and ‘the end’.
with open('Sense and Sensibility.txt', 'r') as myfile:
sas_data = myfile.read().split('SENSE AND SENSIBILITY\n\nby Jane Austen\n\n(1811)')[1].split('THE END')[0].strip()
with open('Emma.txt', 'r') as myfile:
emma_data = myfile.read().split('EMMA\n\nBy Jane Austen')[1].split('FINIS')[0].strip()
with open('Pride and Prejudice.txt', 'r') as myfile:
pap_data = myfile.read().split('PRIDE AND PREJUDICE\n\nBy Jane Austen')[1].split('End of the Project Gutenberg EBook of Pride and Prejudice, by Jane Austen')[0].strip()
Next, I decoded the text, and made some substitutions using the re library, like replacing double hyphens, which Austen sometimes uses when a new speaker starts talking, with a space, and some odd quotation marks with their regular counterparts.
Additionally, the Project Gutenberg versions of both Sense and Sensibility and Emma are split by volume, which I decided to ignore, handling chapters only.
# SaS unicode parsing
sas_data = re.sub('(--)|(_)', ' ', sas_data)
sas_data = unicode(re.sub(r"\s+", " ", sas_data), 'utf-8')
sas_data = re.sub(u"(\u201c|\u201d)", '"', sas_data)
sas_data = re.sub('VOLUME [IXV]+\s+', '', sas_data)
# Emma unicode parsing
emma_data = re.sub('--', ' ', emma_data)
emma_data = unicode(re.sub(r"\s+", " ", emma_data), 'utf-8')
emma_data = re.sub(u"(\u2018|\u2019)", "'", emma_data)
emma_data = re.sub(u"(\u201c|\u201d)", '"', emma_data)
emma_data = re.sub('VOLUME [IXV]+\s+', '', emma_data)
# PaP unicode parsing
pap_data = unicode(re.sub(r"\s+", " ", pap_data), 'utf-8')
pap_data = re.sub(u"(\u2018|\u2019)", "'", pap_data)
pap_data = re.sub(u"(\u201c|\u201d)", '"', pap_data)
Vocabulary Comparison
In order to compare the words Austen uses in each novel, I first needed to clean the text a little and find the unique words in each novel.
def get_word_set(text):
word_set = {word.lower() for word in re.sub(r"[^\w\s']+", ' ', text).split()}
word_set.discard('')
return word_set
# make each long string into a set of unique words
sas_set = get_word_set(sas_data)
emma_set = get_word_set(emma_data)
pap_set = get_word_set(pap_data)
This function returns a set of unique, lower-case words (as found after splitting on whitespace/punctuation).
Doing a quick comparison of unique words per novel versus words per novel, we see that Emma has the most of both category, though the majority of this length must be coming from overlapping words, since Pride and Prejudice has 75% the number of words that Emma does, but 88% the number of unique words. 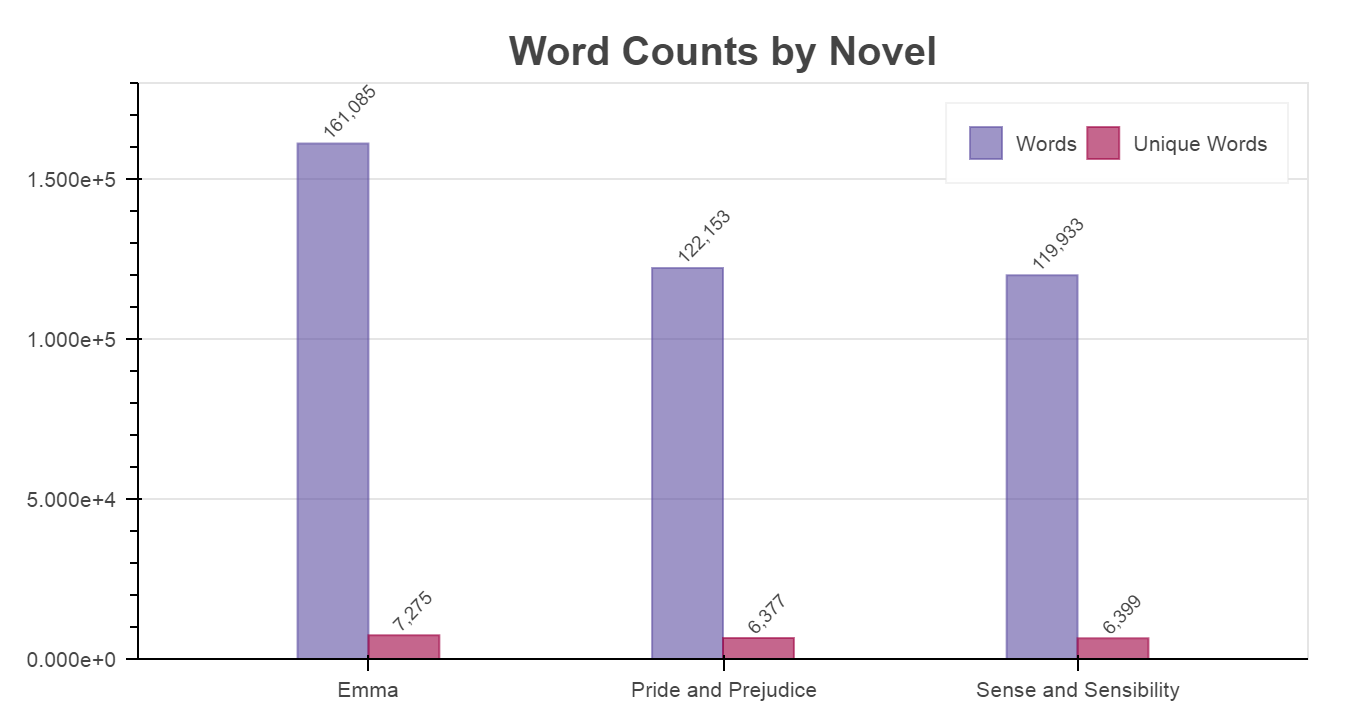
To contrast the vocabularies, I next wanted a venn diagram to illustrate each book’s vocabulary in relation to the others. Rather than writing out each intersection expression to find each section of the venn diagram, I used matplotlib-venn, a small package with functions for plotting area-proportional two- and three-way Venn diagrams in matplotlib.
# plot a venn diagram of overlapping vocabularies
from matplotlib_venn import venn3
venn3([sas_set, pap_set, emma_set], ('Sense and Sensibility', 'Pride and Prejudice', 'Emma'))
plt.show()
This conveniently provided a Venn diagram, with each segment labeled. However, I’m addicted to Bokeh and wanted all my plots to look similar, so I used the numbers to generate a more visually pleasing venn diagram.
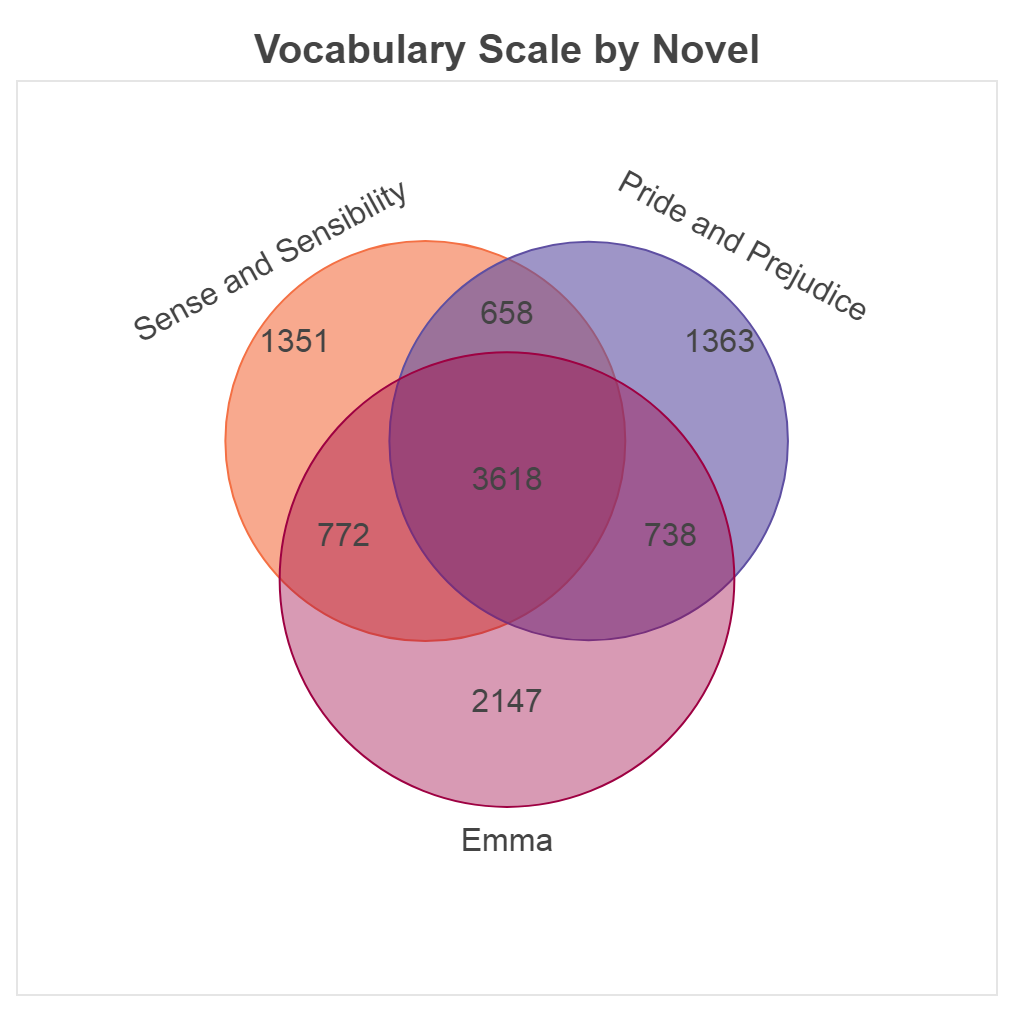
Interestingly, a higher proportion of the unique words Austen used in Emma are also unique to that specific novel, as the 2,147 truly unique words in Emma comprise almost 30% of the 7,275 unique words used in Emma, while both Pride and Prejudice and Sense and Sensibility have lower ratios, both around 21%.
Word Frequencies
Next, I wanted to find word frequencies, but first needed to remove stopwords so my top words weren’t all words like to, the, of, and her…
from nltk.corpus import stopwords
cachedStopWords = stopwords.words("english")+char_names_list
def tag_text(message):
return nltk.pos_tag([word for word in re.findall(r"[a-z']+", message.lower())
if word not in cachedStopWords])
sas_words = pd.DataFrame(tag_text(sas_data), columns=['word', 'pos'])
emma_words = pd.DataFrame(tag_text(emma_data), columns=['word', 'pos'])
pap_words = pd.DataFrame(tag_text(pap_data), columns=['word', 'pos'])
I used the english stopwords from nltk, supplemented with character names from each novel.
The part of speech tagger from nltk is a little too granular for my goals, so I combined the labels I was interested in and disposed of others (like punctuation), using the following:
def condense_pos(df):
df.loc[df['pos'].isin(['JJS', 'JJR']), 'pos'] = 'JJ'
df.loc[df['pos'].isin(['NNP', 'NNPS', 'NNS']), 'pos'] = 'NN'
df.loc[df['pos'].isin(['RBR', 'RBS']), 'pos'] = 'RB'
df.loc[df['pos'].isin(['VBD' 'VBG', 'VBN', 'VBP', 'VBZ']), 'pos'] = 'VB'
return df.loc[df['pos'].isin(['JJ', 'NN', 'RB', 'VB'])]
After condensing the parts of speech, I grouped each dataframe by part of speech and found the 5 most common words for each novel/part of speech combination.
| Emma | Pride and Prejudice | Sense and Sensibility | |
|---|---|---|---|
| Adjectives | good little much great young | much good little great young | much good little great young |
| Nouns | thing time nothing man day | time nothing family room man | time nothing thing sister house |
| Adverbs | well never quite always soon | well never soon however ever | well never soon ever however |
| Verbs | think say know see done | know think say make go | think know say see make |
Clearly, Austen uses most of the same words frequently in each of her novels. A few standouts include:
- family, Pride and Prejudice: Elizabeth, the protagonist, spends the majority of the book embarrassed by her family or dealing with the fallout of their foolish actions. Almost every major plot development is instigated by one of the Bennet family.
- sister, Sense and Sensibility: Rather obvious, as the book centers around the Dashwood sisters, Elinor and Marianne (representing sense and sensibility, respectively).
- go, Pride and Prejudice: Much more so than the other novels, Pride and Prejudice centers around trips, with comings-and-goings to London, Brighton, etc.
“Do they do anything except talk?”
One common complaint against Emma is that nothing ever happens, as the majority of the book is devoted to petty squabbles with little actual action or travel. While this is a highly subjective question, I hypothesized that Emma has proportionally more time devoted to conversations than the other novels.
To demonstrate this, I investigated how much of each book is conversations, which I decided to measure as the ratio of words quoted to total words used.
To extract this ratio, I first needed to ensure that all quotes were separated with a " symbol. This required differentiating between ' in different uses, such as:
'No, my dear, you had better go on horseback...' Mrs. Bennet declared...Mr. Bingley's sister...
I accomplished this with a regular expression that incorporates a forwards and backwards lookup. If the apostrophe appears between two word characters (as in don't), it should not be replaced. Hence, the apostrophe must either have a non-word character before it, or a non-word character after it. Otherwise, it is a single quotation mark, which I replaced with a double quotation mark using re.sub
I then found all sections surrounded by double quotation marks using re.findall, and found the number of words in such sections compared to the number of words in the entire novel, as follows:
def find_conv_ratio(text):
text = re.sub(r"((?<=[^\w])\'|\'(?=[^\w]))", '"', text)
conv_list = ' '.join(re.findall(r'\"[^\"]+\"', text)).split()
all_list = text.split()
return len(conv_list)/float(len(all_list))
Applying this function, I found the following:
| Emma | 49.6% |
| Pride and Prejudice | 51.9% |
| Sense and Sensibility | 45.2% |
I was wrong! Emma actually has a lower percentage of words devoted to conversations than Pride and Prejudice. Of course, you can still find Emma boring, but you can’t blame that on all the talking.
Story Highs and Lows
I next wanted to see if there was a way to extract the flow of the story, using text analysis.
Unsure how to ask a computer to read a book, I decided the closest I could get was a sentiment analysis. I turned once again to VADER (Valence Aware Dictionary and sEntiment Reasoner) (a Python package developed to extract sentiment from blocks of text), which I used in my Edmunds reviews analysis.
I used the compound score (ranges from -1 to 1), defined as:
- Positive sentiment: compound score >= 0.5
- Neutral sentiment: -0.5 < compound score < 0.5)
- Negative sentiment: compound score <= -0.5
I decided to take a rolling average by 100 sentences, as this struck a good balance between reducing noise and retaining overarching patterns. Using np.convolve:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyser = SentimentIntensityAnalyzer()
conv = np.convolve([analyser.polarity_scores(s)['compound'] for s in
nltk.sent_tokenize(text)],
np.ones((100,))/100,
mode='valid')
I also split the raw text into chapter segments, and applied nltk.sent_tokenize to find the number of sentences per chapter (to apropriately label the X axis):
df = pd.DataFrame(columns=['chapter', 'text'])
for index, chapter in enumerate(re.findall('CHAPTER [IVX]+', text)):
df = df.append(pd.Series(['Chapter {}'.format(index+1), chunks[index].strip()],
index=['chapter', 'text']), ignore_index=True)
def num_sentences(group):
return len(nltk.sent_tokenize(group))
#find number of sentences per chapter
df['sentences'] = df['text'].apply(num_sentences)
Using my knowledge of each novel’s plot, I also added some annotations for major plot developments.
First, Emma:
Most of it looks like noise, except for a few outliers, like Chapter 47, when Emma finds out that Frank and Jane are engaged, and she has been wrong about everything for the entire novel as she tries to set up those around her. The range is slight, with a maximum sentiment average of .347 and a minimum of -.062.
Second, Pride and Prejudice:
Here we can see much clearer highs and lows of the novel, closely correlated with major plot occurrences. Most noticeable is the gradual build over the final 3 chapters, leading up to the conclusion (Jane marries Mr. Bingley, Elizabeth marries Mr. Darcy). The range is slightly smaller than that of Emma, with a higher high of .361 average sentiment, and a higher low of -.027. More relevant to note, the standard deviation in rolling sentiment for Pride and Prejudice is 20% larger than that of Emma, implying Emma has, on average, a more even tone, while Pride and Prejudice has more emotional peaks and valleys.
Finally, Sense and Sensibility:
Like Pride and Prejudice, the novel displays very clear highs and lows following the plot, such as the deep low when Willoughby’s engagement is discovered by Marianne. Also note that the range of sentiment here is the widest of all novels, with a high of .433 and a low of -.054.
Indeed, Sense and Sensibility’s standard deviation in rolling average sentiment is 32% larger than that of Emma and 14% larger than that of Pride and Prejudice, implying it is the most tumultuous of the novels. This may be due to Marianne, a prominent supporting character whose emotions (both positive and negative) run very strong.
Character Appearances
I was also interested in tracking character mentions over the course of the book, and applied a similar approach to find which chapters focused on which characters.
I decided to measure this by counting the number of sentences a character’s name was used in each chapter, and then normalizing to find the percentage character mentions by chapter. For smoothness I again used np.convolve, taking a rolling average by 3 chapters.
I chose the characters for each novel, trying to pick the 8 characters I found most important to each story.
To deal with multiple names corresponding to the same character, I used lists of different names that could refer to the same person, trying to be as specific as possible to avoid bleed between relatives.
For example, for Pride and Prejudice:
def count_occurrences(sent_list, char_list):
count = 0
for sentence in sent_list:
for name in char_list:
if name in sentence:
count+=1
break
return count
pap_chars = [['Elizabeth Bennet', 'Elizabeth', 'Lizzie'],
['Jane Bennet', 'Jane', 'Ms. Bennet'],
['George Wickham', 'Wickham'],
['Mr. Darcy', 'Darcy'],
['Mr. Bingley', 'Bingley'],
['Charlotte Lucas', 'Charlotte', 'Ms. Lucas', 'Mrs. Collins'],
['Lady Catherine', 'De Bourgh'],
['Mr. Collins', 'Collins']]
for char_list in pap_chars:
# find occurrences by chapter for character
pap_df[char_list[0]] = pap_df['text'].apply(count_occurrences, char_list=char_list)
# normalize across chapters for percentage
pap_df[char_list[0]] = pap_df[char_list[0]]/sum(pap_df[char_list[0]])
# use np.convolve to take rolling average by 3 chapters
pap_df[char_list[0]] = np.convolve(pap_df[char_list[0]].values, np.ones((3,))/3, mode='same')
First, for Emma:
(Note that the legend is interactive, click to hide/show the corresponding line).
We can see Emma herself is rather constantly mentioned, while more minor characters such as Jane Fairfax and Miss Bates have more prominent spikes as their plot points develop.
Second, for Pride and Prejudice:
We can once again see spikes with relevant plot points, such as Lady Catherine, Charlotte, and Mr. Collins’ mutual spike around chapter 27-30, which detail Elizabeth’s visit to Hunsford. Additionally, Lady Catherine spikes again around chapter 56, when she confronts Elizabeth with her suspicions about Elizabeth and Darcy’s relationship.
Lastly, for Sense and Sensibility:
Unlike the other two novels, we can see two characters who appear midway through the story, with Miss Grey and Lucy Steele showing up around chapters 19 and 26, respectively. Indeed, Miss Grey’s mentions are so concentrated that almost 70% of her mentions occur in chapter 30, as you can see as her line disappears into the stratosphere.
The rest of the characters have rather constant mentions, probably due to no characters embarking on trips in Sense and Sensibility, the way they do in Pride and Prejudice and Emma.
Character Networks
I saw a lot of co-spikes in the previous section, such as the correlation between Mr. Darcy and Mr. Bingley in Pride and Prejudice, and the correlation between Elinor and Marianne Dashwood in Sense and Sensibility. My last task was to map the relationship between various characters.
I decided to measure this by defining a viewpoint character, and measuring relationships between this character and a target character by finding all sentences which mention the viewpoint character. I also extracted the 3 sentences before and the 3 sentences after this sentence, and found the percentage of these segments which mention the target character.
def get_occurrences_by_3(data, name_list):
'''
Finds blocks of 7 sentences, where the 4th sentence mentions the character in the name_list.
'''
sentences = nltk.sent_tokenize(data)
for index,sentence in enumerate(sentences):
for name in name_list:
if name in sentence or name.upper() in sentence:
try:
output.append(" ".join(
[sentences[i] for i in range(max(0,index-3), min(index+3, len(sentences)-1))]
))
except:
output = [" ".join(
[sentences[i] for i in range(max(0,index-3), min(index+3, len(sentences)-1))]
)]
break
return output
def get_relationship_float(data, viewpoint_list, target_list):
'''
Finds the percentage of sentences in 'data' which mention the 'viewpoint' character
and also mention the 'target' character.
'''
subset = get_occurrences_by_3(data, viewpoint_list)
for sentences in subset:
for name in target_list:
if name in sentences or name.upper() in sentences:
try:
output.append(1)
except:
output = [1]
break
try:
return len(output)/float(len(subset))
except:
return 0.
Using permutations from the itertools library, I found all combinations of target and viewpoint characters, and applied the above functions to find the strength of their relationship. For example, for Emma:
emma_chars = [['Emma Woodhouse', 'Emma'],
['Mr. Knightley', 'Knightley'],
['Frank Churchill', 'Frank', 'Mr. Churchill'],
['Jane Fairfax', 'Jane'],
['Harriet Smith', 'Harriet'],
['Miss Bates', 'Bates'],
['Mrs. Weston', 'Taylor'],
['Mr. Elton', 'Elton']]
relation_df = pd.DataFrame()
for viewpoint, target in list(itertools.permutations(emma_chars, 2)):
relation_df = relation_df.append(
pd.Series([viewpoint[0], target[0], get_relationship_float(emma_data, viewpoint, target)],
index=['viewpoint', 'target', 'score']),
ignore_index=True)
Plugging these into a clock-style visualization, first for Emma:
We can see Emma, the protagonist, has the most evenly distributed co-occurrences across all other characters. Every other character has the highest co-occurrence with Emma, but (rather interestingly) the final matches can not be perceived based on co-occurrence. Frank Churchill, who ultimately marries Jane Fairfax, has the same relationship similarity with her as he does with Harriet Smith. For her part, Jane has a greater relationship with both Mr. Knightley and Mr. Elton than she does with her fiancee, Frank.
Second, for Pride and Prejudice:
Here we can see two segments of characters: the first Elizabeth, Jane, Mr. Bingley, and Mr. Darcy, and the second Lady Catherine, Mr. Collins, and Charlotte Lucas. Wickham, something of a dramatic plot point personified, has close ties with Elizabeth, who he courts, and Mr. Darcy, who is both a childhood friend and present rival. Interestingly Charlotte bucks the trend of all supporting characters being most connected to the protagonist, having a stronger relationship with Mr. Collins than she does with the protagonist, Elizabeth.
Lastly, for Sense and Sensibility:
Miss Grey, like Charlotte from Pride and Prejudice, is an exception to the rule as she is most strongly linked to Willoughby, not Elinor. We can also see the strong link between the Dashwood sisters, as both Elinor and Marianne are almost uniformly the strongest two connections any other character has, probably due to their own shockingly high co-occurrence score (Elinor appears in 77% of Marianne’s mentions!).
Conclusion
How can you choose a winner? Emma has the largest vocabulary, but Pride and Prejudice the most complicated character networks. Sense and Sensibility is certainly the most emotional read, with hyper-dramatic characters.
Despite all the measuring, poking, and prodding at the text I did, I leave it up to the reader to select their favorite, hopefully after reading the novels rather than just analyzing them.
But for myself, Pride and Prejudice will always remain the favorite.
Code
All analysis was completed using Python 2.7, relying primarily on the pandas, re, nltk, and Bokeh libraries. All code can be found in my Example Projects git repository.