Webscraping 101 with Selenium
I’ve used Selenium before to scrape data from Allrecipes.com (specifically for my first post using R), but re-wrote my scraper to be more comprehensive and more flexible since then. Rather than simply using it to acquire data for my next project, I decided to also outline how the scraper works for anyone who wants a working Selenium example with explanations.
Selenium Basics
Selenium is a tool that opens and controls a web browser programatically, and is highly useful for automating repetitive and potentially time-consuming tasks, like downloading documents or filling out a timesheet. In this example, I’ll use Selenium to repeatedly open webpages and acquire the information in the HTML of each page.
The Python library that I use for this project has plenty of documentation available online, and provides an easy way for Python programmers to design programs that require accessing websites as if they were an actual frontend user.
The first thing you’ll need, in addition to the library, is a webdriver, which actually opens your browser. I use Google Chrome as my preferred browser, and in this exercise used the chrome webdriver.
Program Overview
My goal is to acquire data from a “large number” of recipes for each “category” that Allrecipes.com defines.
The program will start at allrecipes.com’s categories overview page, and save links to each “relevant” individual subcategory page. From there, it will scrape each subcategory page to get “enough” recipe links per subcategory. Then it will bulk-scrape each of the recipe links, getting all the data off each page.
Note: quotes imply a user-defined parameter.
Starting a Session
To start up the webdriver, we’ll need the actual Python webdriver module, as well as some options to go along with it.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
The most important arguments to add (for this specific project) are:
- headless
This will “open” a browser, but without creating an actual window you can open and watch. During development of a Selenium program, leave this argument out so you can see how your scraper is navigating the web.
- log-level=3
Selenium is highly vocal (prints a lot to stdout), so if you’d like to suppress these messages, the easiest way I’ve found is to change the log level to 3, leaving space for your custom messages to actually be seen.
Syntax as follows:
loc = 'C:\...\chromedriver.exe' #location of Chrome webdriver
options = Options()
options.add_argument('--headless')
options.add_argument('--log-level=3')
driver = webdriver.Chrome(loc, chrome_options=options)
Navigating
Selenium is able to click, scroll, enter text, submit forms, and perform pretty much any tasks a human in charge of a web browser could.
Home Page
The most basic command, get, tells the web driver to navigate to a webpage, like entering the address in the browser’s search bar.
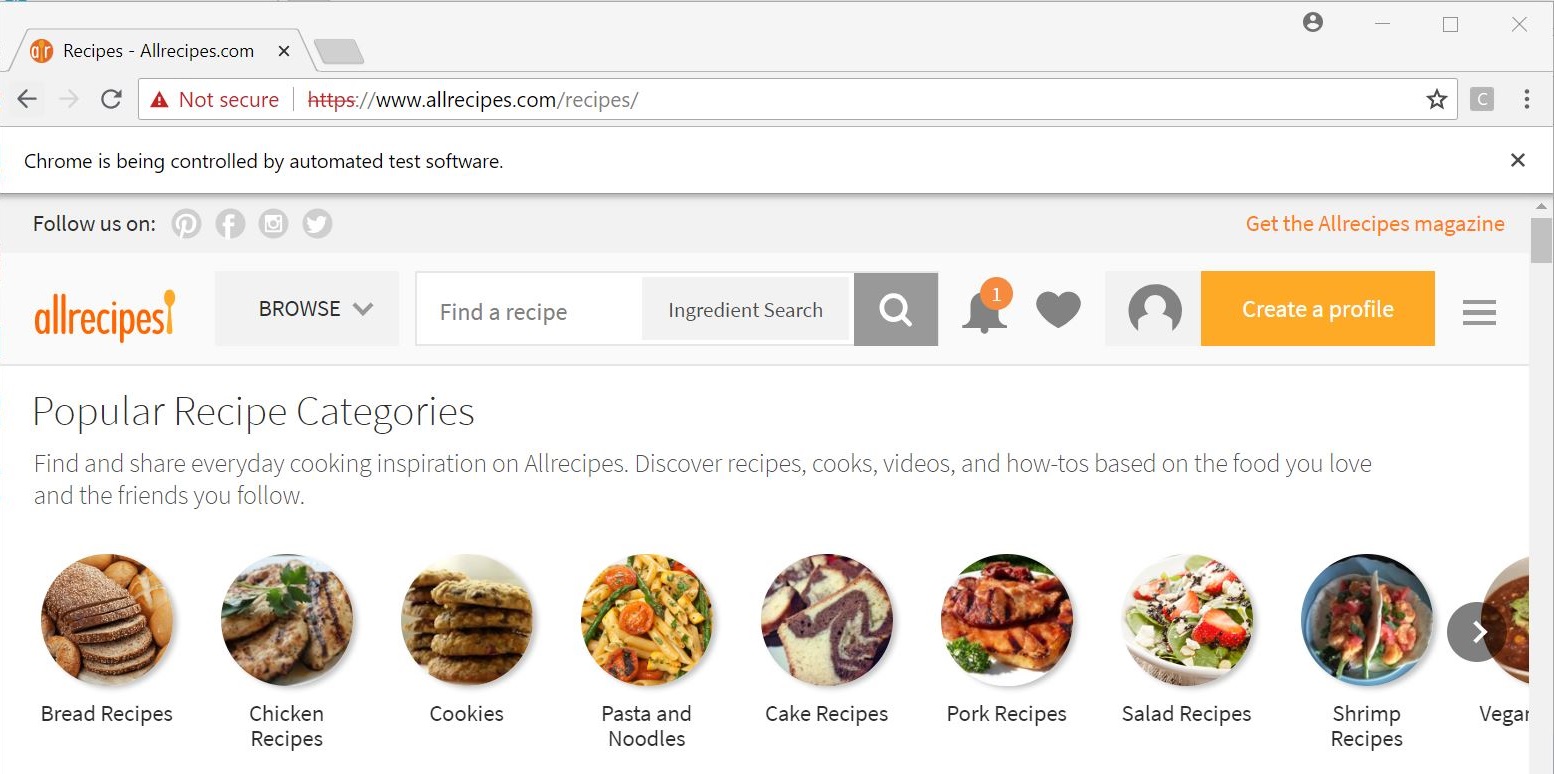
In our case, the program will start with navigating to the categories overview page:
driver.get('https://www.allrecipes.com/recipes/')
For reference, the page looks like this: 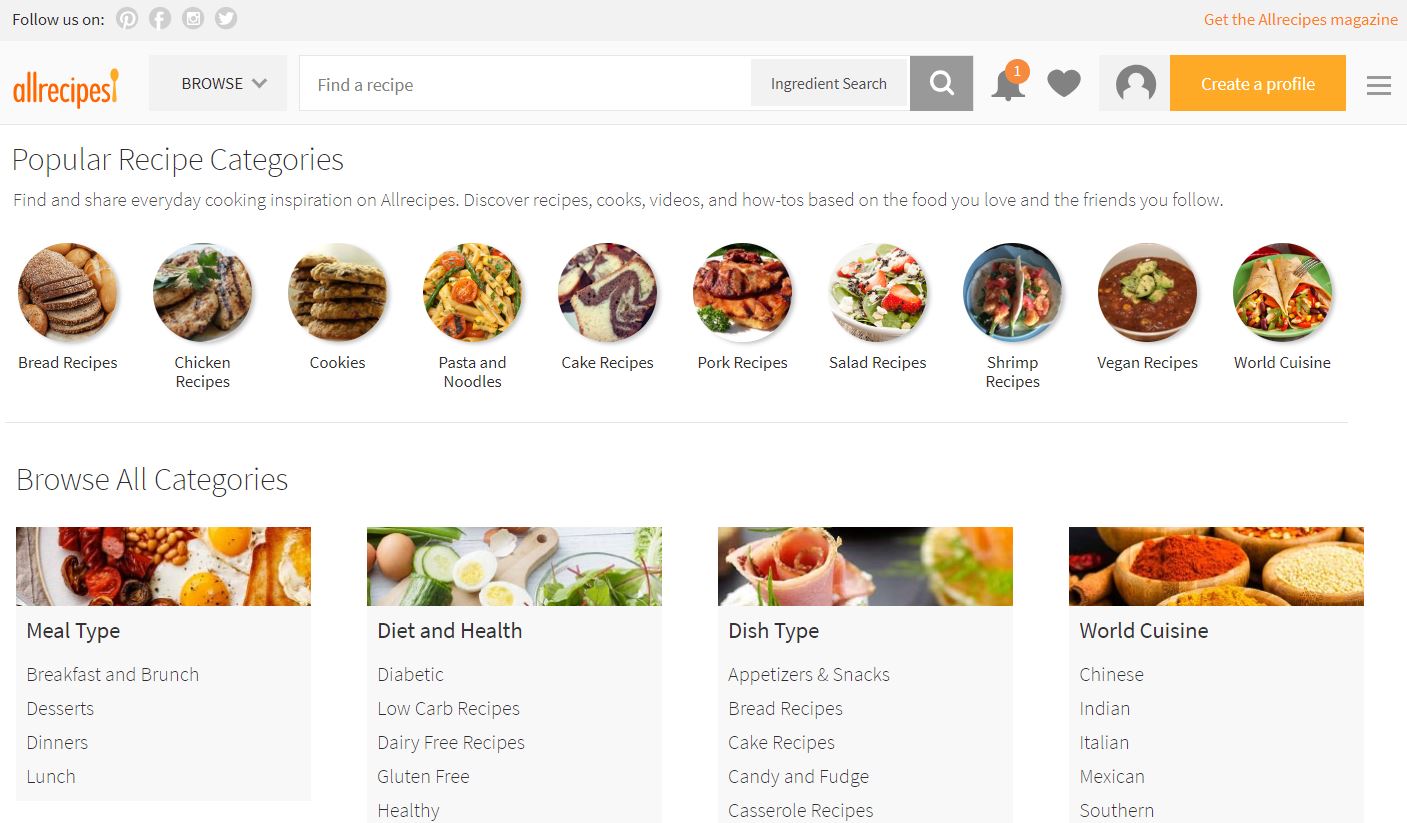
What we’re really concerned with is the “Browse All Categories” section. We want to pull the titles and links of each subcategory, with some “filtering”. For example, say we’re only concerned with the World Cuisine category: 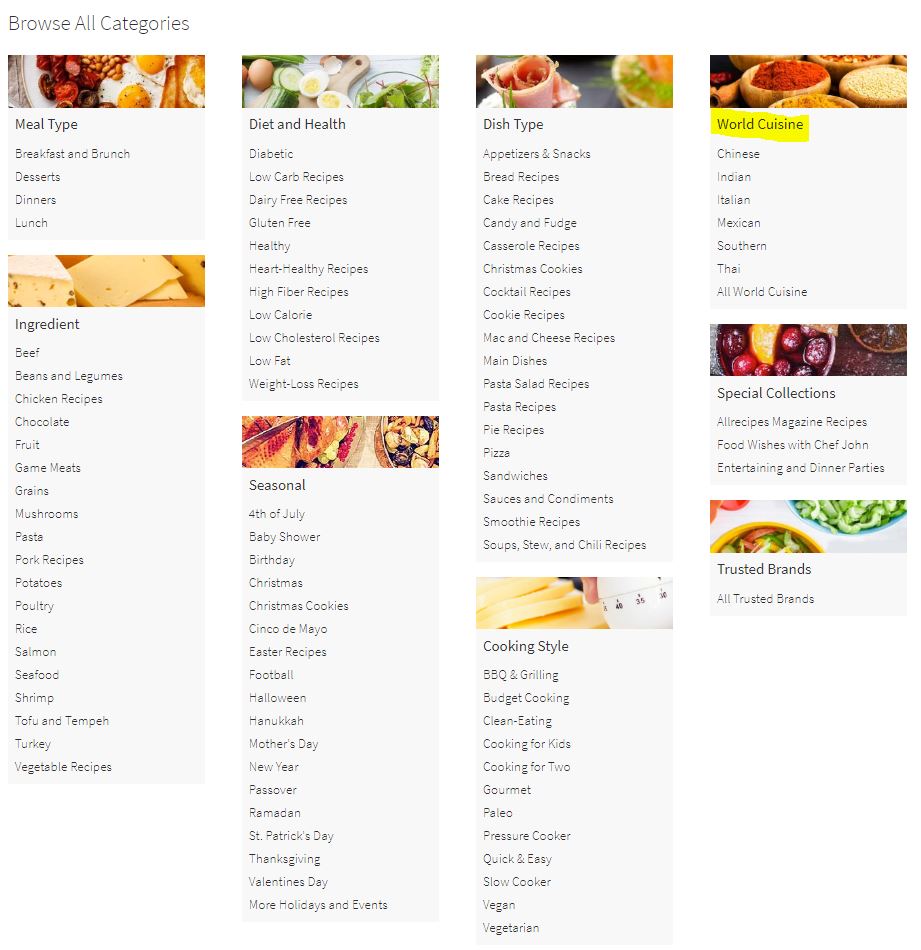 Therefore, we want the titles and links associated with Chinese, Indian, Italian, etc. cuisines.
Therefore, we want the titles and links associated with Chinese, Indian, Italian, etc. cuisines.
major_cats = {'World Cuisine'} # names of Allrecipes.com major categories (section headers) to scrape
# initialize df to hold category information
cat_df = pd.DataFrame(columns=['cat', 'subcat', 'link'])
# iterate over sections
for section in driver.find_elements_by_xpath("//div[@class='all-categories-col']//section"):
section_name = section.find_elements_by_xpath(".//h3[@class='heading__h3']")[0].text
# skip some categories
if section_name not in major_cats:
continue
# retain the subcategory name and link for the remaining categories
cat_df = pd.concat([cat_df,
pd.DataFrame([(section_name, a.text,a.get_attribute('href'))
for a in section.find_elements_by_xpath(".//ul//li//a")],
columns=['cat', 'subcat', 'link'])])
I won’t go into depth about selecting items using HTML here. Just note this will select 9 elements (Meal Type, Ingredient, Diet and Health, Seasonal, etc.) and check what their title is. If the title is one of the major categories we’re interested in, only then will it select sub-elements (the links we’re interested in) and get the link text (titles) and URLs.
Subcategory Pages
Allrecipes.com has a pinterest-style infinite scroll design, which is useful for our purposes. We’ll have the driver navigate to each subcategory page (for example, Italian), and scroll down until “enough” recipe tiles load on the page. All we’ll store in our dataframe at this point is the recipe link and (identified with dummy variables) the subcategory it comes from.
For reference, the recipe tiles look like this: 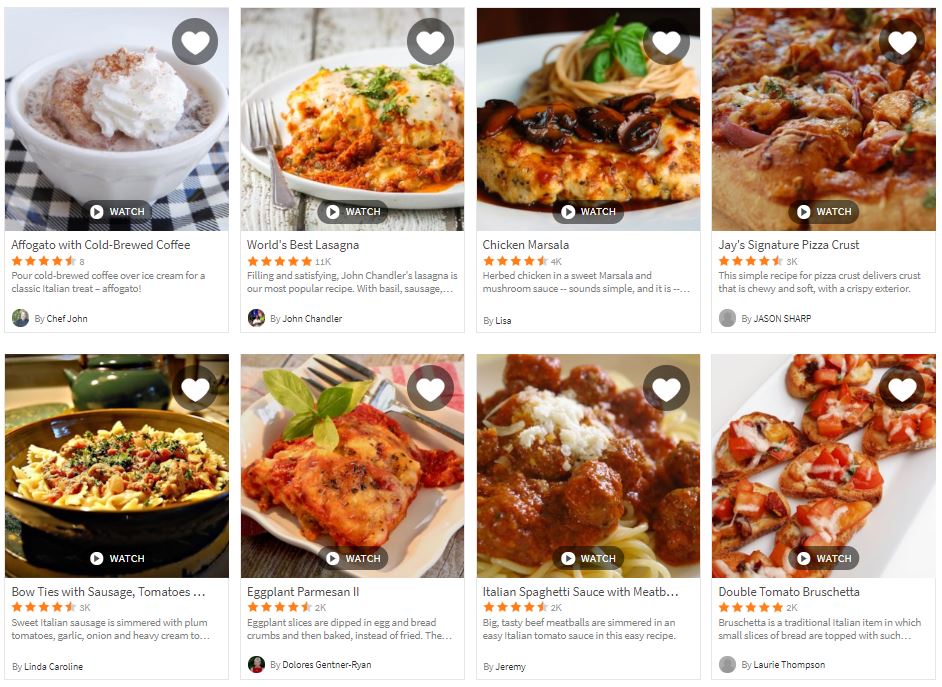
Note a quirk of the infinite scroll is that occasionally a More button appears at the bottom of the screen and must be clicked before scrolling down has any effect. However, this button is not available all the time and will throw an error if you click it when it isn’t visible, so we’ll use Selenium’s Element Not Visible exception.
from selenium.common.exceptions import ElementNotVisibleException as NotVisible
num_per_category = 20 #the number of recipes to retrieve from each subcategory
# either read previous version or start over
try:
data = pd.read_csv("data_before_scraping.csv", index_col=0)
except:
# columns for link and dummies for subcategory
data = pd.DataFrame(columns=['link']+cat_df['subcat'].values.tolist())
# iterate through category pages to find recipe links for each category
for index, (subcat, link) in cat_df[['subcat', 'link']].iterrows():
# skip if category has already been covered
if data[subcat].sum()>0:
continue
# otherwise, go to category page and scrape links
driver.get(link)
# keep scrolling down until enough links appear
links = driver.find_elements_by_xpath("//article//div//h3[@class='fixed-recipe-card__h3']//a")
last_size = len(links)
while last_size<num_per_category:
# check if "more results" button has appeared and click if necessary
try:
driver.find_element_by_id("btnMoreResults").click()
except NotVisible:
pass
# scroll window down and wait for it to load
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # for politeness and loading time
links = driver.find_elements_by_xpath("//article//div//h3[@class='fixed-recipe-card__h3']//a")
# exit if scrolling down doesn't load more links (infinite scroll error in webpage)
if len(links)==last_size:
break
last_size = len(links)
# update user on status
print("Finished scraping '{}' category with {} recipe links.".format(subcat, last_size))
# add data to dataframe
new_data = pd.DataFrame([[card.get_attribute('href') for card in links]], index=['link']).T.reindex(columns=data.columns, fill_value=0)
new_data[subcat] = 1
data = pd.concat([data, new_data])
# all data has been scraped
## remove internalSource extras in string links
data['link'] = data['link'].apply(lambda x:x.split("?internalSource")[0])
## groupby link and aggregate multiple rows of the same link into a single row
data = data.groupby('link').sum().reset_index()
## reindex to add columns for each recipe
data_to_scrape = ['title', 'ratings', 'madeit', 'reviews', 'photos', 'submitter_description',
'ingredients', 'readyin', 'servings', 'calories', 'fat', 'carbohydrate', 'protein']
data = data.reindex(columns=data.columns.tolist()+data_to_scrape)
Getting Recipe Pages
Now we have links to each page, all we need to do is scrape them!
First, a function that takes a single row of the dataframe we built previously, nagivates to the link, and then scrapes the information off the page. Note this process is identical to that I used during my previous post that involved acquiring data from Allrecipes.com.
def scrape_recipe_link(s, driver):
# if row has been updated before, don't scrape again
if len(s['title'])!=0:
return s
#navigate to recipe
driver.get(s['link'])
- The function picks out the basics, such as the title of the recipe and social metrics, like the number of photos associated with the recipe, the number of people who indicated they had made it, and the number of reviews of the recipe.
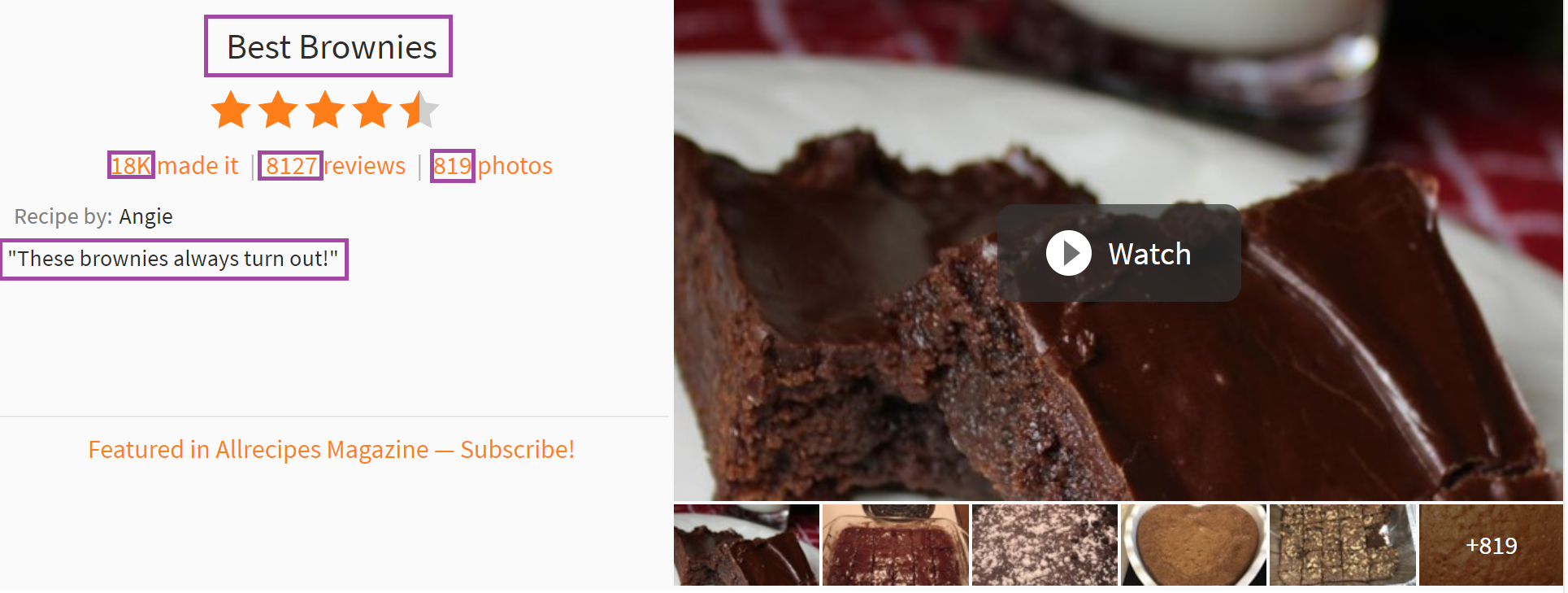
try: s.loc['title'] = driver.find_elements_by_xpath("//h1[@class='recipe-summary__h1']")[0].text except: pass try: s.loc['ratings'] = driver.find_elements_by_xpath("//div[@class='rating-stars']")[0].get_attribute('data-ratingstars') except: pass try: s.loc['madeit'] = driver.find_elements_by_xpath("//span[@class='made-it-count ng-binding']")[0].text except: pass try: s.loc['reviews'] = driver.find_elements_by_xpath("//span[@class='review-count']")[0].text.split()[0] except: pass try: s.loc['photos'] = driver.find_elements_by_xpath("//span[@class='picture-count-link']")[0].text.split()[0] except: pass try: s.loc['submitter_description'] = driver.find_elements_by_xpath("//div[@class='submitter__description']")[0].text except: pass - It also pulls the list of ingredients in each recipe, and the number of servings the recipe makes.
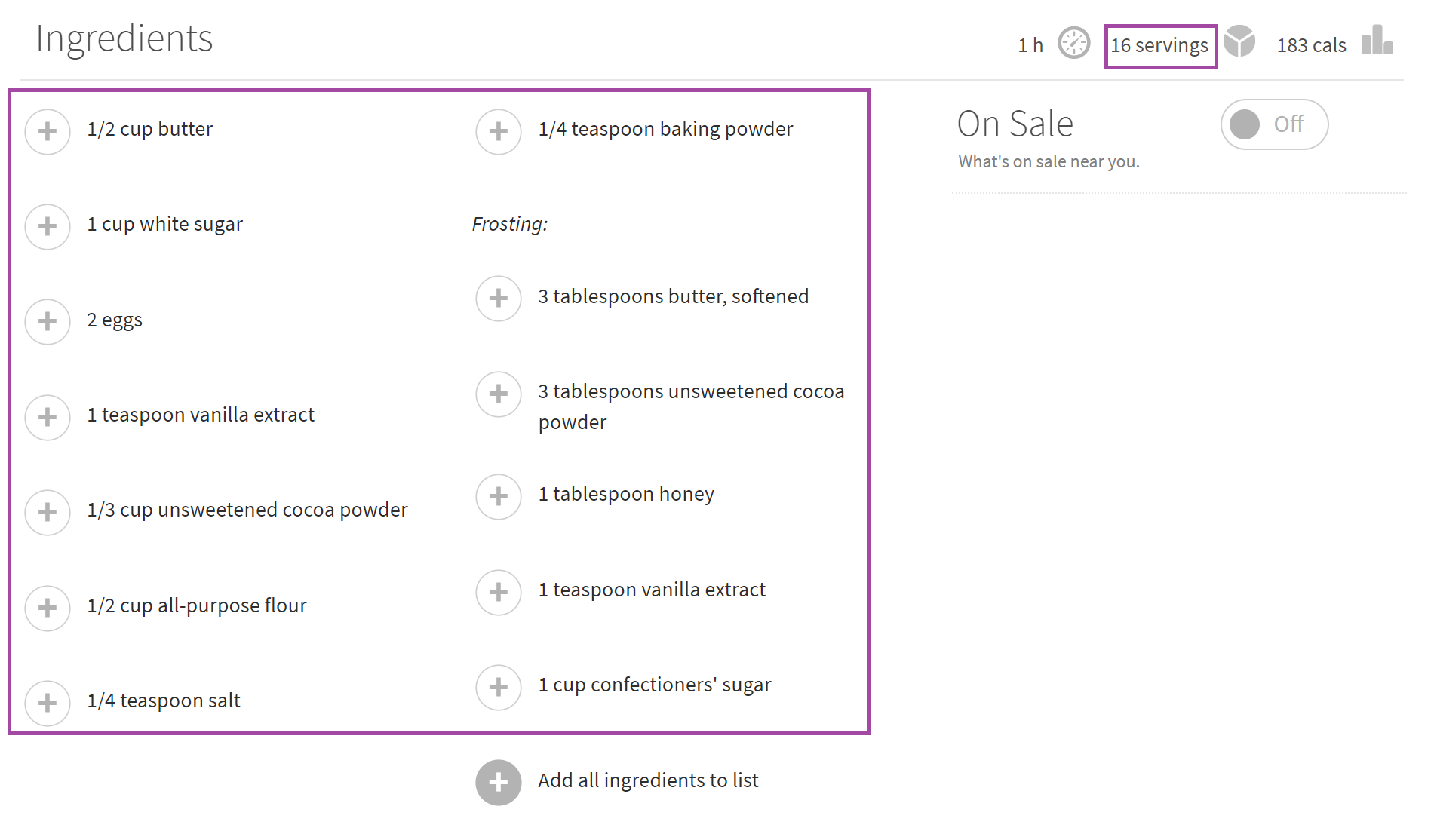
try: s.loc['ingredients'] = [element.text for element in driver.find_elements_by_xpath("//span[@class='recipe-ingred_txt added']")] except: pass try: s.loc['servings'] = driver.find_elements_by_xpath("//span[@class='servings-count']//span")[0].text except: pass - Finally, it acquires the nutrition breakdown for each recipe - calories, carbs, fat, and protein (all by serving), as well as the amount of time the recipe takes to complete.
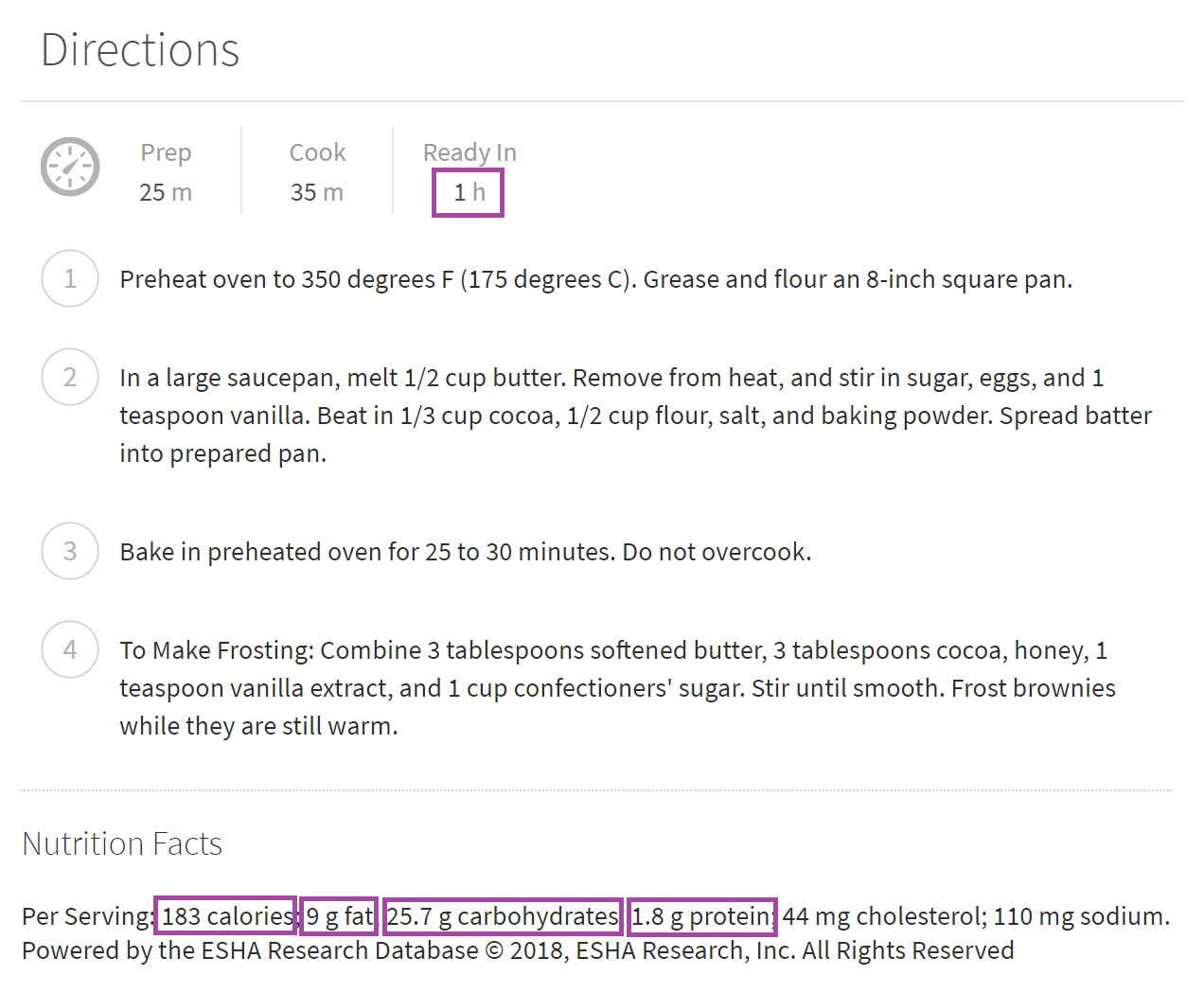
try:
s.loc['readyin'] = driver.find_elements_by_xpath("//span[@class='ready-in-time']")[0].text
except:
pass
try:
s.loc['calories'] = driver.find_elements_by_xpath("//span[@class='calorie-count']//span")[0].text
except:
pass
for string in ['fatContent', 'carbohydrateContent', 'proteinContent']:
try:
s.loc[re.split(r"[A-Z]", string)[0]] = driver.find_elements_by_xpath("//span[@itemprop='{}']".format(string))[0].text
except:
pass
return s
Just apply this to each row in the dataframe, and voilà. Data for days. It’ll take time to run, but overnight should be more than enough for a reasonable number of recipes per category (less than 100) and a moderate number of categories (3 major categories).
The full .py file is available in my Example Projects git repository. I designed it to save intermediate steps, so it should be possible to force quit the program and resume it later, allowing you to split the time required for scraping into smaller chunks.
Code
Scraping was completed using Python 3.6.5, relying primarily on selenium and pandas, but also using the re, os, and time libraries.
All code can be found in my Example Projects git repository.
An analysis post will follow.